Reconnaissance d’Entités Nommées (NER). État de l’art à partir d’un cas pratique
Ce billet est une synthèse rédigée par Alexia Schneider à la fin de son stage au sein du service Bibliothèque et données numériques de la Bibliothèque Nationale et Universitaire de Strasbourg sous l’encadrement de Rosanne Wingert. Les travaux qu’il présente sont un exemple des expérimentations engagées au sein de l’équipe technique d’Estrade.
La Reconnaissance d’Entités Nommées : une tâche de TAL pour l’annotation automatique
Aussi appelé NER pour Named Entity Recognition, la reconnaissance d’Entités Nommées (EN) consiste à identifier dans un texte non structuré des noms de personnes, de lieux, mais aussi des symboles ou des dates. La tâche peut paraître simple mais pose en réalité encore des difficultés quand il s’agit de l’automatiser. Si les modèles de langue actuels encodent leurs données de préentraînement de telle sorte que les mots les plus courants sont replacés dans leur contexte, il n’est pas toujours aisé de distinguer un patronyme d’un nom de profession, ou encore une date d’un numéro de page, pour peu que ces éléments soient spécifiques à un corpus. Cet article présente différentes méthodes qui recourt au Traitement Automatique des Langues (TAL) pour la tâche de NER dans le contexte de données bibliographiques.
Répertoires bibliographiques : le Ritter comme cas d’usage
Les répertoires bibliographiques sont des ouvrages qui recensent d’autres ouvrages. Ces catalogues respectent une structure visant à simplifier leur lecture et à uniformiser le travail de répertoriage. Le Répertoire bibliographique des livres imprimés en Alsace aux XVe et XVIe siècles), de François Ritter (1876-1969) aussi appelé pour cette raison « le Ritter », servira d’exemple tout au long de l’article.

Page de 3e de couverture du Ritter

Une page du premier volume du Ritter
La page en illustration montre bien la structure d’un volume : chaque ouvrage recensé est cité dans une notice numérotée en bas à droite. En tête de notice se trouve le nom de l’auteur, ici en lettres capitales, suivi du titre de l’œuvre, ici entre parenthèses, de la ville publication/d’impression, de l’éditeur et de la date de publication. On trouve ensuite, quand l’information est donnée, le format du document (par exemple : in folio/ in quarto). Un saut de ligne marque dans ce répertoire les notes : à savoir les autres répertoires qui recensent le document. Dans quelques cas on trouvera aussi mention de la provenance de l’ouvrage, de notes manuscrites ou encore de marques atypiques. Ainsi la notice 1263 répertorie le Dictionarium d’Ambrosius Capelinus, document in-folio imprimé à Haguenau par Thomas Anshelm en juillet 1522. Ce document est mentionné dans le répertoire Burg au numéro 131a, mais aussi dans un autre volume du Ritter aux numéros 401 et 402. Malheureusement, tout le Ritter ne respecte pas ce format. Le répertoire totalise plus de 2 500 pages dont à peu près 2 000 pages de notices réparties en sept volumes qui ont été publiés entre 1937 et 1960. François Ritter a changé de méthode de répertoriage au fur et à mesure des volumes, comme on le voit dans les illustrations suivantes :


Dès le deuxième volume, François Ritter travaille déjà bien différemment : ses notices sont plus complètes avec des commentaires sur les ornements, le marquage des sauts de ligne avec le symbole pipe « | » pour retranscrire l’intégralité de la page de titre. Il utilise aussi l’emphase typographique pour partager la lecture de la notice entre son travail, en italique, et le texte cité de l’ouvrage, en romain. Les sept volumes ont été édité de 1937 à 1960. Le troisième volume a été publié pendant l’Occupation allemande, ce qui explique que les notices soient rédigées en allemand.
En plus de la question de la position des informations sur la page, il faut aussi s’intéresser aux données elles-mêmes. Comme le suggère son titre, le Répertoire bibliographique des livres imprimés en Alsace aux XVe et XVIe siècles représente des données restreintes géographiquement et temporellement, ce qui est un avantage pour la reconnaissance de noms de personnes et de noms de lieux et de date. Cependant, l’orthographe des noms propres n’est pas encore standardisée aux XVe et XVIe siècles et Ritter a tenté bien souvent de retranscrire le nom tel que donné dans l’ouvrage. Ainsi la ville de Strasbourg, en plus d’être orthographiée dans l’adresse bibliographique « Strassburg » dans le volume 3 en allemand, se trouve aussi dans les retranscriptions de page de titre sous les orthographes « Strazburg » ou encore « Argentoratum » nom d’origine de la ville fondée par les Romains au 1er siècle AEC.
Ainsi, le Ritter est un défi intéressant pour une tâche d’automatisation de la NER : il contient à la fois une structure attendue et des particularités importantes qui limitent l’emploi d’un système d’extraction à partir d’une position sur la page ou d’un vocabulaire limité. Quelles méthodes peuvent alors être appliquées sur le Ritter ? La section suivante retrace la méthodologie des expérimentations effectuées lors d’un stage de quatre mois au sein du service Bibliothèque et données numériques de la Bibliothèque Nationale et Universitaire de Strasbourg.
Méthodologie
Tout d’abord, cinquante pages de notices ont été annotées manuellement pour constituer une « vérité de terrain ». Cette vérité de terrain est utile pour l’évaluation des prédictions générées automatiquement mais aussi pour l’entraînement d’algorithmes de classification. L’annotation a été effectuée à partir de document XML-ALTO avec l’ajout de balises placeName, persName, date, balises appartenant au vocabulaire de la TEI. La structure des pages en notices a été annotée à l’aide d’éléments div avec un attribut @type à deux valeurs : « notice » et « renvoi ». L’illustration présente le résultat de l’annotation manuelle.
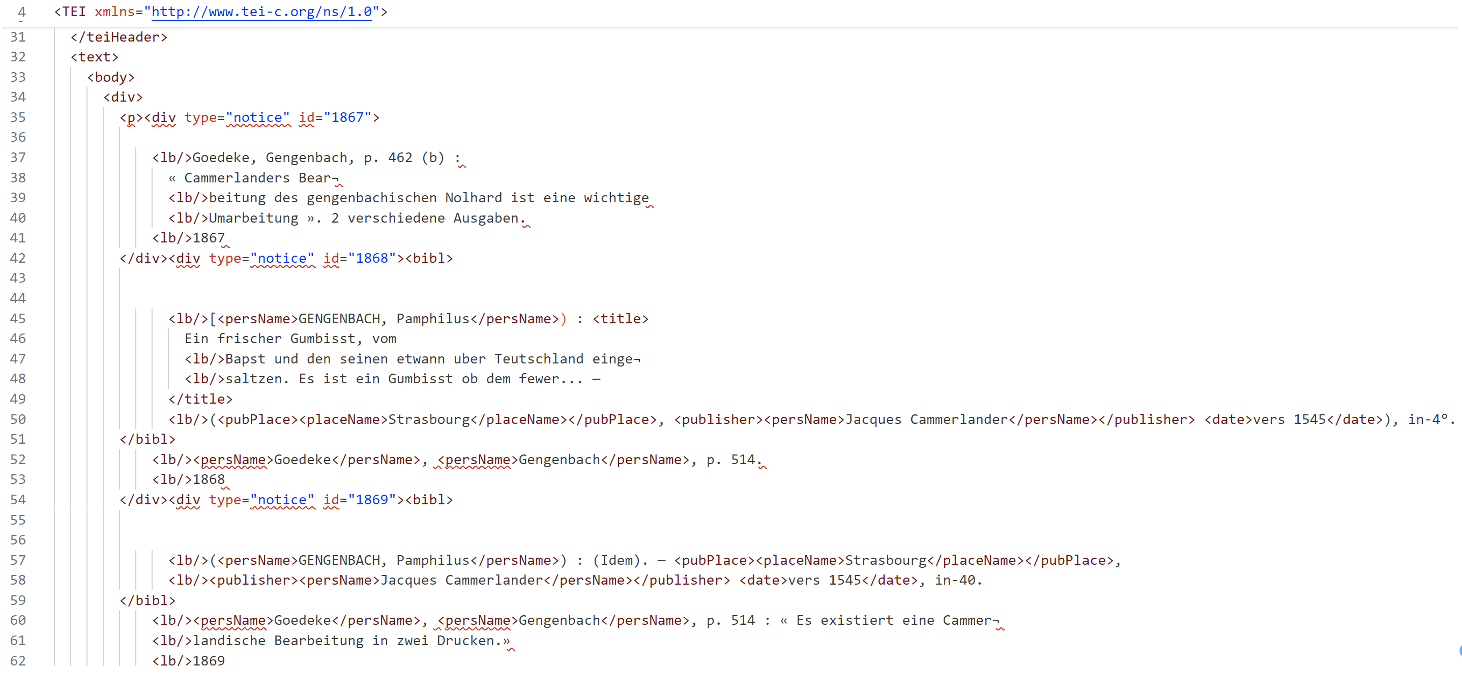
Une page du Ritter encodée en XML dont les éléments d’EN sont encodés manuellement
Les pages ont ensuite été traitées par notice afin d’obtenir des jeux d’entraînement, de test et d’évaluation. Le jeu d’entraînement comprend 171 notices et le jeu d’évaluation 43 notices totalisant 214 notices. Les données ont été tokenisées pour l’évaluation de la NER en fonction du modèle employé. Dans la mesure où il fallait que le modèle prédise un nom complet afin que ce nom puisse être aligné avec son identifiant IdRef (URI), j’ai employé le système OIB, (Outside, Inside, Beginning) afin de déterminer si l’étiquette d’un token correspondait au premier token de l’EN ou à un token suivant. Exemple : le nom « WOLF Thomas jun. », constitué de trois mots ou tokens est étiqueté comme suit :
WOLF : B-PER[^ I-PER désigne le nom d’une personne. B-PER désigne le début du nom d’une personne juste après le nom d’une autre personne.] Thomas : I-PER jun. : I-PER
Les tokens qui ne correspondent pas à une entité nommée sont tous étiquetés « O » pour « other ». Le texte de la notice peut être tokenisée comme dans l’exemple suivant avec la méthode « split » de Python, c’est-à-dire avec un découpage du texte selon les espaces. Les EN sont aussi identifiable grâce à leur position dans le texte en fonction de leur index. Le Tableau 1 montre le résultat du prétraitement pour une notice annotée manuellement.
| Notice originale | Tokens | Etiquettes | Position des EN |
|---|---|---|---|
| WOLF Thomas jun., Responsiva. Voir : WIMPHELING, Adoles¬ centia . Haguenau, H. Gran, 1508. R101.064; n° 2484. | ‘ ‘, ‘WOLF’, ‘Thomas’, ‘jun.’, ‘,’, ‘‘, ‘Responsiva’, ‘.’, ‘Voir’, ‘:’, ‘‘, ‘WIMPHELING’, ‘,’, ‘‘, ‘‘, ‘‘, ‘Adoles¬’, ‘‘, ‘‘, ‘centia’, ‘‘, ‘‘, ‘.’, ‘‘, ‘Haguenau’, ‘,’, ‘‘, ‘H.’, ‘Gran’, ‘,’, ‘‘, ‘1508’, ‘.’, ‘R101.064;’, ‘n°’, ‘2484.’, | ‘O’, ‘B-PER’, ‘I-PER’, ‘I-PER’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘B-PER’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘B-LOC’, ‘O’, ‘O’, ‘B-PER’, ‘I-PER’, ‘O’, ‘O’, ‘B-DATE’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’ | (1, 5, ‘B-PER’), (6, 12, ‘I-PER’), (13, 17, ‘I-PER’), (38, 48, ‘B-PER’), (69, 77, ‘B-LOC’), (79, 81, ‘B-PER’), (82, 86, ‘I-PER’), (88, 92, ‘B-DATE’) |
Tableau 1 Une notice tokenisée avec des EN étiquetées
Deux approches ont été testées. La première vise à employer des modèles « généralistes » qui n’ont pas de connaissances spécifiques sur le Ritter, mais qui peuvent être spécialisés sur la tâche de reconnaissance de noms propres. La deuxième vise à spécialiser un modèle sur nos données (le Ritter) et sur notre tâche (la NER). Il faut garder à l’esprit que de très nombreux modèles existent déjà pour la reconnaissance d’Entités Nommées et qu’une spécialisation a un coût en temps et en effort, en plus d’avoir un impact écologique. Les modèles appelés ici « généralistes » sont : - wikineural-multilingual-ner de Babelscape (WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER). BERT multilingue (9 langues) affiné sur le wikineural dataset. - Camembert-ner-with-dates de Jean-Baptiste Polle. Camembert (BERT préentraîné sur des données en français) affiné sur le wikiner-fr dataset.
Les modèles généralistes et spécialisés

Table alphabétique des noms propres du Ritter
Tout d’abord, j’ai conçu un système « expert » à partir de l’exploitation de données déjà connues et vérifiées, à savoir la liste alphabétique des noms de personnes et de bibliothèque dressé dans les index qui se situent à la fin du Ritter. Cette automatisation est une recherche de correspondance textuelle à l’aide d’expressions rationnelles (ou « regex »). Les noms ont été extraits de la table alphabétique, également avec des regex. Cette stratégie nécessite peu de moyen et a l’avantage de permettre un contrôle total sur les données en sortie, mais il a l’inconvénient majeur de ne fonctionner que sur ce répertoire, ce qui le disqualifie pour la généralisation à d’autres données bibliographiques. Ensuite, j’ai cherché à apprendre à des modèles de langue les connaissances nécessaires à la NER pour le Ritter. Une première possibilité consiste à solliciter des large language models (ou LLMs) génératifs en leur donnant des exemples directement dans la requête (ou prompt). Dans ce cas, seules quelques phrases données à titre d’exemples suffisent à améliorer la capacité de ces modèles à répondre à la tâche demandée.
Le prompt donné au modèle de Mistral est le suivant, (suivi de plusieurs notices du Ritter dont il faut extraire les EN). Le format de réponse demandé est du JSON (pertinent pour le stockage d’informations).
Prompt : « Extrait en un fichier JSON les entités nommées B-PER, I-PER, B-LOC, I-LOC, B-DATE, I-DATE.
Exemples = "HANNENBEIN, Georg . Voir: LIED (Neu Klaglied der Bauern) n° 340.PETRUS DE CRESCENTIS ( WUERFELBUCH ] Strasbourg , ( Christian Egenolff ), 1529 Marque typ. de Chris. Egenolff. Anno M. D. LXXXII Stadtbibl. Strassburg 1192".
Réponse =
[[{'entity': 'B-PER',
'word': 'HANNENBEIN',},
{'entity': 'I-PER',
'word': ',',},
{'entity': 'I-PER',
'word': 'Georg',},
],[{'entity': 'B-PER',
'word': 'PETRUS',},
{'entity': 'I-PER',
'word': 'DE',
},{'entity': 'I-PER',
'word': 'CRESCENTIS',},
],[{'entity':'B-LOC',
'word': 'Strasbourg',
},],[{'entity': 'B-PER',
'word': 'Christian'
},{'entity':'I-PER',
'word': 'Egenolff'},],
[{'entity': 'B-DATE',
'word': '1529'}
,],[{'entity':'B-PER',
'word': 'Chris.'},
{'entity': 'I-PER',
'word': 'Egenolff'},
],[{'entity':'B-DATE',
'word': 'M.'},
{'entity': 'I-DATE',
'word': 'D.'},
{'entity':'I-DATE',
'word': 'LXXXII'},
],[{'entity': 'B-LOC',
'word': 'Strassburg'}]]
Cet apprentissage en contexte se révèle une stratégie compétitive par rapport au système à base de règle précédemment cité, notamment quand elle est appliquée à des modèles récents comme Mistral-large de Mistral AI. Cette stratégie a l’avantage de ne nécessiter aucune connaissance en programmation et ne demande qu’un prétraitement léger. Le prétraitement consiste à diviser l’intégralité du texte en batches dont le nombre de tokens permettent au modèle de traiter la demande avec justesse. En effet, les LLM ont une fenêtre contextuelle variable (32 000 tokens pour mistral-large), mais le modèle perd en efficacité avec des textes à traiter trop longs. De plus, si l’on ajoute une requête comprenant des exemples, cela réduit encore le nombre de pages à traiter simultanément.
Une seconde possibilité pour l’apprentissage de données spécifiques est de procéder à un apprentissage par transfert ou transfert learning. Cela consiste à exploiter un volume plus large de données annotées manuellement pour entraîner un modèle, non seulement sur des données précises, mais aussi sur une tâche. C’est à partir de l’affinage de certains Transformers de type BERT que les modèles appelés dans le cadre de mes expérimentations « généralistes » ont été entraîné à la tâche de NER. Cette stratégie a permis d’obtenir un modèle dont les performances sont comparables aux deux autres stratégies citées, mais surtout, en fait un modèle applicable à d’autres données du même type sans ajustement.
Résultats
Les métriques d’évaluation sont la précision, le rappel et la mesure F1. Je ne présente pour simplifier la lecture des résultats que la moyenne F1 pondérée par classe.
| Modèles | Mesure F1 pondérée par classe |
|---|---|
| Modèles “généralistes” | |
| camembert-ner-with-dates | 0,53 |
| wikineural-multilingual-ner | 0,76 |
| Modèles « spécialistes » | |
| Regex | 0,86 |
| Mistral-Large | 0,82 |
| frcamembertritter | 0,80 |
Tableau 2 : Évaluation des modèles sur 43 notices du Ritter
Le Tableau 2 récapitule les performances globales des modèles expérimentés. Ce que l’on voit, tout d’abord, c’est qu’un modèle qui n’a pas de connaissances particulières sur des données pourtant très spécifiques peut produire une extraction d’Entités Nommées approchante à celle d’un modèle spécialisé. En effet, les scores F1 du modèle multilingue de Babelscape (0,76) et du modèle frcamembertritter (0,80) qui est camembert-base affiné sur 171 notices du Ritter, sont très proches.
Cependant, un modèle trop spécifique, comme le système à base de regex, n’est pas à même d’être utilisé sur de nouvelles données. La spécialisation à partir d’une relativement petite quantité de données (50 page /2 000 pages de notices) s’est montrée utile à la fois pour prendre connaissance des données en elles-mêmes, et pour obtenir un modèle capable de traiter des données similaires, ce qui fait de cette stratégie un compromis intéressant en termes de reproductibilité et de qualité des résultats.
Le modèle spécialisé, nommé frcamembertlarge (il s’agit de camembert-base affiné sur cinquante pages du Ritter) est disponible sur HuggingFace et peut être utilisé avec la bibliothèque Python spaCy sur n’importe quelle donnée en XML ou en TXT grâce au programme doc2xmlencodedner.py développé pour ce projet. Quant au Répertoire bibliographique des livres imprimés en Alsace aux XVe et XVIe siècles, l’intégralité a été encodée automatiquement en XML avec ce modèle et peut être réutilisé pour d’autres projets (voir ici). Les noms de personnes bénéficient par ailleurs d’un attribut « idref » contenant leur URI extrait automatiquement depuis le site http://www.idref.fr. Des informations complémentaires sont disponibles dans la documentation du dépôt GitHub dédié.

Une page du Ritter encodée automatiquement en XML avec noms de personnes, de lieux et date obtenus avec le modèle frcamembertritter
Conclusion
L’automatisation de l’annotation sémantique sur des données bibliographiques telles que le Répertoire bibliographique des livres imprimés en Alsace aux XVe et XVIe siècles de François Ritter reste une tâche difficile qui présente un intérêt pour les bibliothèques et la communauté scientifique. Bien que des outils et bibliothèques de TAL simples et prêts à l’emploi existent pour extraire automatiquement des informations spécifiques, la structure complexe et les particularités du Ritter m’ont incitée à explorer la piste de la spécialisation sous la forme d’un apprentissage en contexte ou d’un transfert learning. L’évaluation de différentes stratégies a montré que la spécialisation d’un modèle sur un ensemble de données spécifiques, bien qu’elle demande plus de temps et d’efforts, offre de meilleures performances et surtout une plus grande adaptabilité à d’autres données similaires.
Références
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. de las, Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., & Sayed, W. E. (2023). Mistral 7B (arXiv:2310.06825). arXiv. Disponible en ligne https://doi.org/10.48550/arXiv.2310.06825, consulté le 1 septembre 2024.
- Martin, L., Muller, B., Ortiz Suárez, P. J., Dupont, Y., Romary, L., de la Clergerie, É., Seddah, D., & Sagot, B. (2020). CamemBERT : A Tasty French Language Model. In D. Jurafsky, J. Chai, N. Schluter, & J. Tetreault (Éds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (p. 7203 7219). Association for Computational Linguistics. Disponible en ligne https://doi.org/10.18653/v1/2020.acl-main.645, consulté le 1 septembre 2024.
- Polle, J.-B. (2023). Jean-Baptiste/camembert-ner-with-dates at main [Logiciel]. Disponible en ligne https://huggingface.co/Jean-Baptiste/camembert-ner-with-dates/tree/main, consulté le 1 septembre 2024.
- Ritter, F. (1938). Catalogue des incunables alsaciens de la bibliothèque nationale et universitaire de Strasbourg.
- Schneider, A. (2024). Frcamembertritter (Revision 4819b24). Hugging Face. Disponible en ligne https://doi.org/10.57967/hf/2721, consulté le 1 septembre 2024.
- Simone Tedeschi, Valentino Maiorca, Niccolò Campolungo, Francesco Cecconi, and Roberto Navigli. 2021. WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. In Findings of the Association for Computational Linguistics, EMNLP 2021, pages 2521–2533, Punta Cana, Dominican Republic. Association for Computational Linguistics. Disponible en ligne https://aclanthology.org/2021.findings-emnlp.215/, consulté le 1 septembre 2024.